南昌軟件與服務外包產業發展現狀與展望

南昌作為江西省的省會城市,近年來在軟件與服務外包領域展現出強勁的發展勢頭。依托當地豐富的人才資源、優越的區位條件和不斷優化的政策環境,南昌正逐步成為中部地區重要的軟件外包服務基地。
南昌軟件外包服務的發展得益于其扎實的產業基礎。南昌擁有多所高校和科研院所,為軟件行業輸送了大量專業技術人才。政府積極推動軟件產業園區的建設,吸引了眾多國內外知名企業入駐,形成了較為完整的產業鏈。
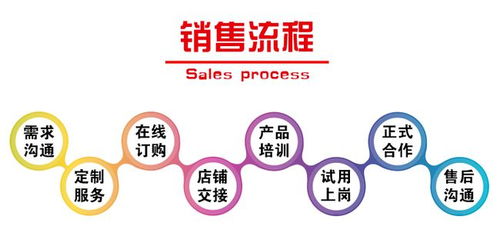
在服務外包領域,南昌企業專注于軟件開發、信息技術服務、業務流程外包等多個方向。特別是在金融、醫療、教育等行業的應用軟件開發方面,南昌的企業已經積累了豐富的經驗,能夠為客戶提供高質量、定制化的解決方案。
值得一提的是,南昌軟件外包服務企業注重技術創新和質量管理。許多企業已通過CMMI、ISO等國際認證,具備承接國際項目的能力。隨著云計算、大數據、人工智能等新技術的應用,南昌的軟件外包服務正向更高附加值的方向轉型升級。
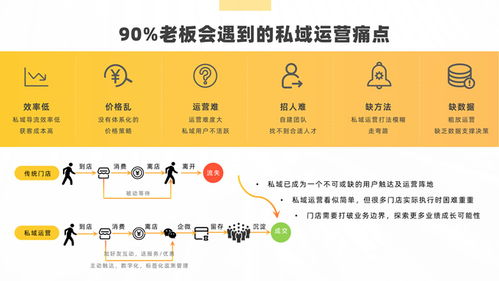
南昌軟件外包產業也面臨一些挑戰,如高端人才相對短缺、國際市場競爭激烈等。南昌需要進一步加強人才培養和引進,提升創新能力,拓展國際市場,推動軟件與服務外包產業向高質量發展邁進。
南昌軟件與服務外包產業具有良好的發展前景。在政府支持和企業努力的共同推動下,南昌有望打造更具競爭力的軟件外包服務產業集群,為當地經濟發展注入新的活力。
如若轉載,請注明出處:http://m.sxbona.cn/product/40.html
更新時間:2026-01-07 16:41:07